17 apr
grafikkort

Nvidia har afsløret sin seneste AI chip kaldet Blackwell, der er 30 gange hurtigere ved visse opgaver end dens forgænger. Firmaet, der sidder med en markedsandel på 80%, håber at cementere sin dominans på markedet. Foruden B200 "Blackwell" chippen, detaljerede firmaets administrerende direktør Jensen Huang en ny række softwareværktøjer ved firmaets årlige udviklerkonference.
Opkaldt efter Dr. David Harold Blackwell, en amerikansk pioner inden for statistik og matematik, der blandt andet skrev den første Bayesian statistik lærebog, er Blackwell-arkitekturen endnu en gang NVIDIA, der satser stort på mange af virksomhedens AI designs. NVIDIA har noget rigtig godt kørende med Hopper (og Ampere før det), og overordnet set sigter Blackwell på at bringe mere af det samme, men med flere funktioner, mere fleksibilitet og flere transistorer.

Det første, der skal bemærkes, er, at Blackwell GPU'en bliver stor. Bogstaveligt talt. B200-modulerne, den skal indgå i, vil have to GPU-dies på en enkelt pakke. NVIDIA er endelig gået over til chiplet designs med deres flagship GPU'er. Mens de ikke afslører størrelsen på de individuelle dies, får vi at vide, at de er "reticle-sized" dies, hvilket burde sætte dem et sted over 800mm2 hver. GH100-dien var allerede tæt på TSMC's 4nm reticle-grænser, så der er meget lidt plads til, at NVIDIA kan vokse her - i det mindste uden at forblive inden for en enkelt die.
Mærkværdigt nok, på trods af disse pladsbegrænsninger på dies, bruger NVIDIA ikke en TSMC 3nm-klasse node til Blackwell. Teknisk set bruger de en ny node - TSMC 4NP - men dette er blot en højtydende version af 4N-noden, der blev brugt til GH100-GPU'en. Dette betyder, at stort set alle Blackwells effektivitetsgevinster skal komme fra arkitektonisk effektivitet, mens en blanding af denne effektivitet og størrelsen på at skalere ud vil levere Blackwells samlede ydeevneforbedringer.
På trods af at de holder sig til en 4nm-klasse node, har NVIDIA formået at presse flere transistorer ind i en enkelt die. Transistortællingen for den komplette accelerator ligger på 208 milliarder, eller 104 milliarder transistorer pr. die. GH100 var 80 milliarder transistorer, så hver B100-die har omkring 30% flere transistorer samlet set, en beskeden gevinst sammenlignet med historiske standarder. Hvilket igen er grunden til, at vi ser NVIDIA anvende flere dies til deres komplette GPU.
For deres første multi-die chip er NVIDIA fast besluttet på at springe den akavede fase med "to acceleratorer på én chip" over og gå direkte til at få hele acceleratoren til at opføre sig som én enkelt chip. Ifølge NVIDIA fungerer de to dies som "en forenet CUDA GPU", der tilbyder fuld ydeevne uden kompromiser. Nøglen til dette er den høje båndbredde I/O-forbindelse mellem dies, som NVIDIA kalder NV-High Bandwidth Interface (NV-HBI), og tilbyder 10TB/sekund af båndbredde. Formodentlig er det i samlet form, hvilket betyder, at diesene kan sende 5TB/sekund i hver retning samtidigt.

På B200 er hver die parret med 4 stakke af HBM3E-hukommelse, i alt 8 stakke i alt, hvilket danner en effektiv hukommelsesbusbredde på 8192-bits. En af de begrænsende faktorer i alle AI-acceleratorer har været hukommelseskapacitet (uden at undervurdere behovet for båndbredde også), så at kunne inkludere flere stakke er enormt i forbedringen af acceleratorens lokale hukommelseskapacitet. Samlet set tilbyder B200 192 GB HBM3E, eller 24 GB pr. stak, hvilket er identisk med kapaciteten på 24 GB pr. stak for H200 (og 50% mere hukommelse end de originale 16 GB pr. stak H100).
Ifølge NVIDIA har chippen en samlet HBM-hukommelsesbåndbredde på 8TB/sekund, hvilket svarer til 1TB/sekund pr. stak – eller en datarate på 8Gbps/pin. Som vi har bemærket i vores tidligere dækning af HBM3E, er hukommelsen i sidste ende designet til at nå op på 9,2Gbps/pin eller bedre, men vi ser ofte NVIDIA være lidt konservativ med clockhastighederne for deres server-acceleratorer. Uanset hvad, er dette næsten 2,4 gange så meget hukommelsesbåndbredde som H100 (eller 66% mere end H200), så NVIDIA oplever en markant stigning i båndbredde.
Endelig har vi for øjeblikket ingen oplysninger om TDP for en enkelt B200-accelerator. Uden tvivl vil det være højt – man kan ikke mere end fordoble sine transistorer i en og undgå en form for straf i form af strømforbrug. NVIDIA vil sælge både luftkølede DGX-systemer og væskekølede NVL72-racks, så B200 er ikke uden for luftkølingens rækkevidde.

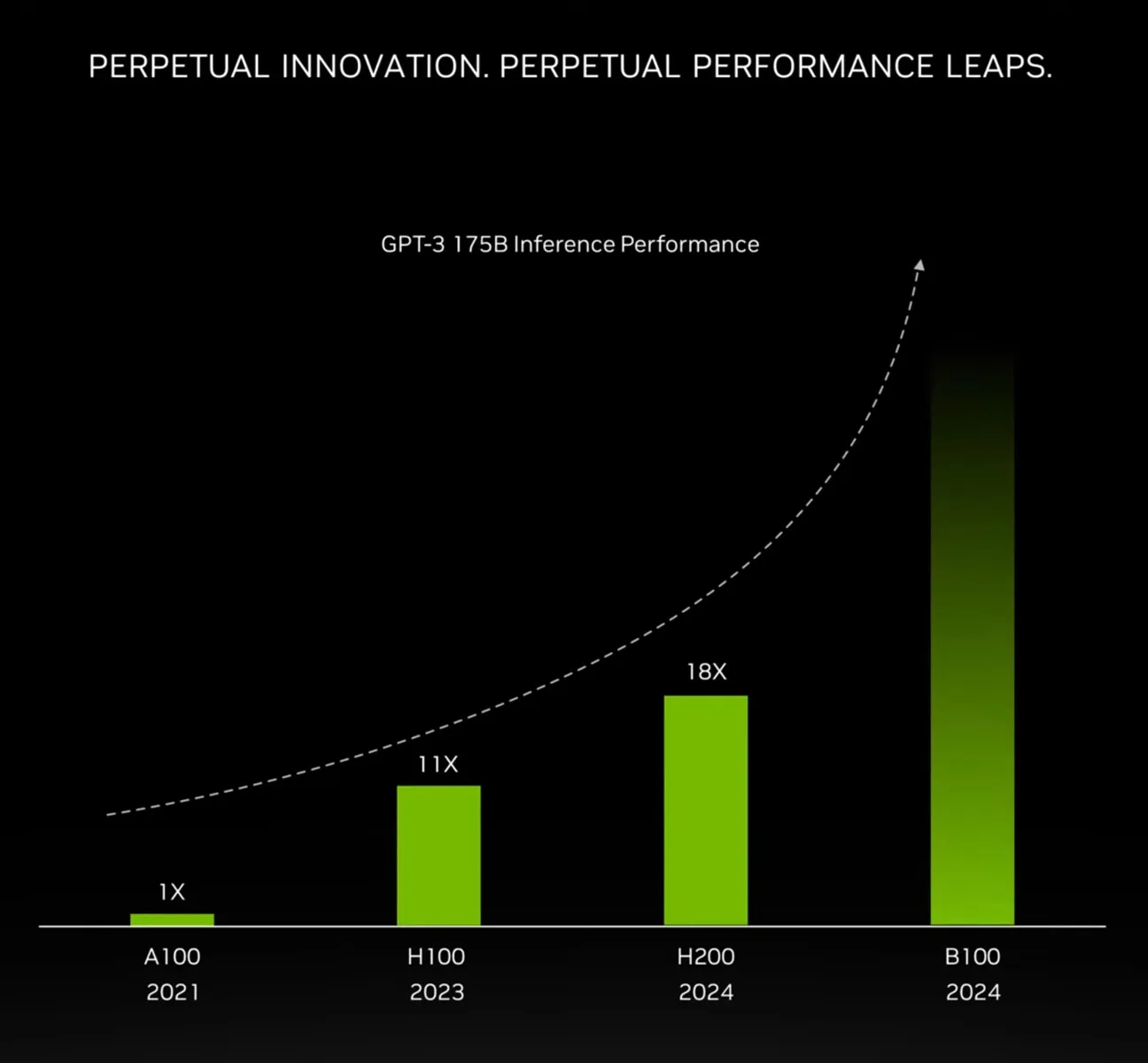
Overordnet set sigter NVIDIA mod en 4x stigning i træningsydelse i forhold til H100 på klyngeniveau, og en endnu større 30x stigning i inferensydelse, samtidig med at de gør dette med 25x større energieffektivitet.
Nvidia er det tredje mest værdifulde selskab i USA, kun overgået af Microsoft og Apple. Dets aktier er steget med 240% det sidste år, og dets markedsværdi nåede $2tn sidste måned.
Da hr. Huang kickstartede konferencen, sagde han spøgefuldt, "Jeg håber, I er klar over, at det her ikke er en koncert." Nvidia sagde, at store kunder som Amazon, Google, Microsoft og OpenAI forventes at bruge firmaets nye flagskibschip i cloud-computing-tjenester og til deres egne AI-tilbud. Det sagde også, at de nye softwareværktøjer, kaldet mikro-tjenester, forbedrer systemeffektiviteten og gør det lettere for en virksomhed at integrere en AI-model i sit arbejde.
Andre meddelelser inkluderer en ny serie af chips til biler, der kan køre chatbots inde i køretøjet. Firmaet sagde, at de kinesiske elbilproducenter BYD og Xpeng begge ville bruge deres nye chips. Hr. Huang skitserede også en ny serie af chips til at skabe menneskelignende robotter og inviterede flere af robotterne op på scenen sammen med ham.




